
Degenerate Feedback Loops in Machine Learning
This problem goes unnoticed by many data scientist and machine learning engineers when designing and deploying machine learning models in the industry. Let's learn what it is and how to fix it!

What is a Degenerate Feedback Loop?
Let’s assume you are training a Machine Learning model for a bank to decide whether each customer is “a good customer” (default is unlikely) or “a bad customer” (default is likely). We can call this our “approval model.”
You used data from the company's customers and finally created a model with reasonable precision. By your calculations, it should be highly profitable (as estimated by the customer’s default reduction). Therefore, the “approval model” goes to production, and now every customer will either be approved or denied following the model prediction.
After a couple of months, you have gathered more data (new customers and more default info about old customers) and decided to retrain the model, trying to increase the model’s precision. And so you did: your retrained model and achieved a higher precision.
You might think: Well, it’s time to go to production by replacing the old model, right? However, there is a hidden problem that goes by many professionals.
Look at the diagram that represents this flow:
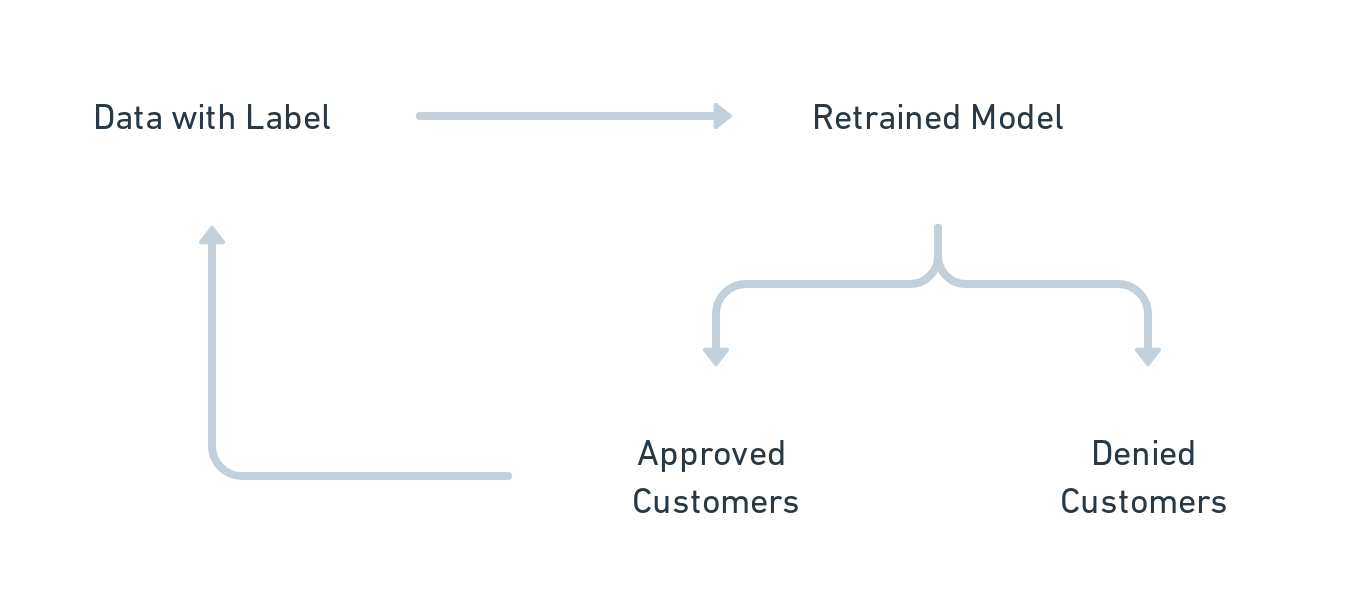
The problem here is: Because we cannot generate the “label” (whether a customer defaulted or not) for denied customers, we generate selection bias in our model. This poses two issues, mainly:
There might be many good customers in the “denied” population, but our model cannot identify them because we never approve them.
The problem aggravates with every retraining — because within the approved population, the only mistake the model makes is to “approve a ‘bad’ customer.” Hence, the incentive is to create a more strict model every time.
Hopefully, this exemplified well what a degenerate feedback loop is, but here I follow with an excellent quote:
“A degenerate feedback loop is created when a system’s outputs are used to create or process the same system’s inputs, which, in turn, influence the system’s future outputs” — by Chip Huyen
Here are some more examples of the Degenerate Feedback Loop:
Fraud / Crime Analysis: Model that sends to the analysis suspicious financial behaviors, and we don’t get the info about the “not suspicious.”
Credit Lines: Model that decides how much credit we should give a customer. We don’t have the information on what would happen with customers if they received a lower or higher line than recommended.
Search Engines / Recommendations: In recommender systems, if you present the user with a list, there is a natural “position bias,” in which users typically already click the first results. (we don’t get the info about what would happen if the order was different)
Geographical Predictions: If a model predicts crime-rate for different locations, and we use that to send more cops to certain places, we might get more crime reports in a region just because there are more cops there. We get the data about areas with no/few cops.
Tip: To identify whether there might be a degenerate feedback loop problem, you can continually monitor population diversity, comparing the data you trained your model on with the population you are scoring the model with.
Solution #1: Sampling
Well, if we do not have the data for part of the population, we can create ways of gathering it. The most common approach is to use a random sampling strategy.
Using the example above of “customers approval/denial,” we can set a small percentage of customers to approve regardless of the model's prediction. This can also be useful to compare the performance of the model in comparison to a randomized approach.
Mathematically, this is a very sound solution; however, when applying this logic in real businesses, we must be extra careful. In this example, significant losses might occur if we bring too many “risky” customers. Therefore, we should try to set a “reasonable” sampling ratio considering our business requirements and, if necessary, apply other policies to mitigate the risk you are creating. As a Data Scientist, I incentivize you to advocate for this process in your team, as it will bring long-term benefits.
More tips…
Weighting: When sampling and retraining your model, you should consider your sample's representativeness. Depending on the modeling technique you are using, it might be a good idea to assign greater weights or oversample/undersample to balance out the populations to reflect the production distribution.
Reinforcement Learning: You can increment the sampling strategy with more advanced techniques, such as the ones based on Reinforcement Learning, as this can easily be framed as an “exploration-exploitation” process. Still, if the randomized approach is not that costly for your application, getting that extra data with the “randomness” property should be pretty valuable.
Solution #2: Counterfactual
We can try another approach when we have a feedback loop that only affects some of the outputs.
Let’s assume you have a model that predicts whether the person would click on that recommendation. Here we have the feedback loop problem because people naturally click more on the first options (known as position preference).
A straightforward approach to overcome this is that you may gather the data of your model (features and label) and create an additional feature to each instance indicating if your label (click or no-click) happened when it was the first in the order or not. After training our model on that data, we can, for a given instance, force the flag 0 (not first). This way, we remove some of the bias of the cases always in the first position. See this flow below:
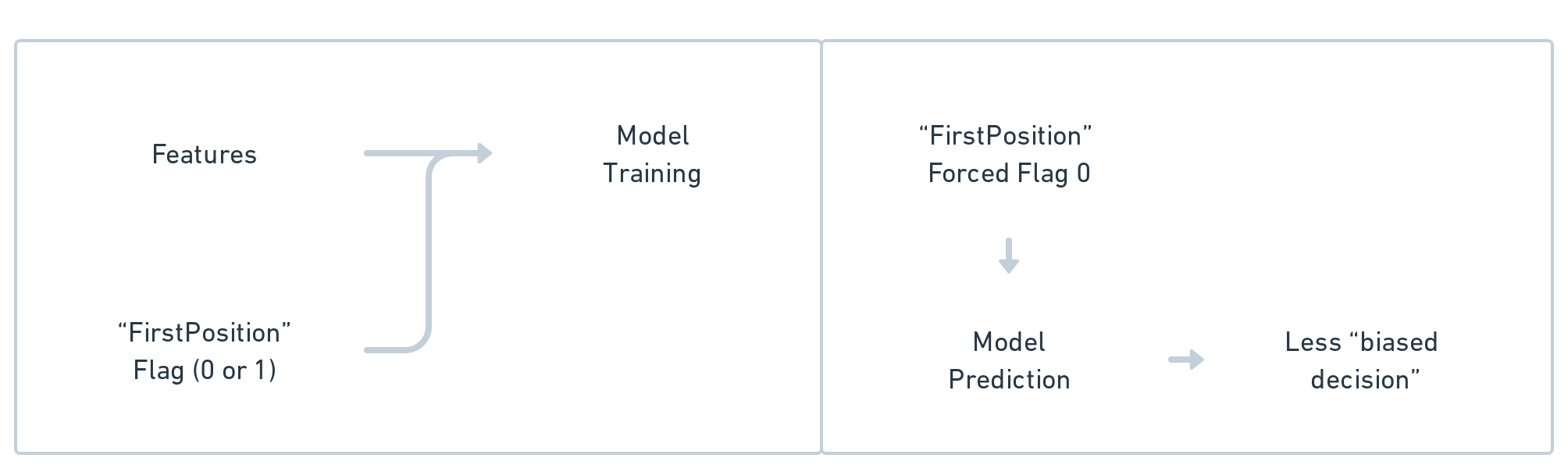
This is known as “The Counterfactual Model,” as we want to know what would have happened if a different course of action had been taken (if our prediction was not for a “first position” item, would it still be this relevant?)
Of course, this process can apply to other scenarios. Credit limit policies can benefit significantly from this, as we may want to know, “if we had a different credit limit, would this person still not default?”
If you want to dive deeper into how a mature company like Google does it, you can watch this video, which explains their study “Recommending What Video to Watch Next: A Multitask Ranking System.”
For recommendation models, there are also some metrics to assess whether we have a feedback loop problem: Average Rec Popularity (ARP), Average Percentage of Long Tail Items (APLT), and measuring the Hit Rate against Popularity Buckets. [Metrics explained here]
Conclusion
Despite following the modeling methodology step by step, data scientists can easily fall into the degenerate feedback loop trap, which will most likely generate long-term problems. However, by considering the entire application flow early on, we can anticipate it and implement the proper mitigation solution.
I hope you found this helpful. Good luck with your feedback loops!