
7 Things to Study in ML: Beyond the Basics
Topics to take your ML knowledge to the next level.

After learning the entire ML Pipeline (pre-processing, some models, evaluation methods, and basic deployment), I’ve seen many people struggling to progress further in the field. They know there’s probably still a lot to learn but don’t know what exactly.
In this article, I selected some topics extremely relevant to AI professionals. I will explain what they are and recommend where you should start for each of them.
1. Interpretability
Models generate predictions. However, those predictions by themselves might not be enough:
You might be developing an application that requires telling WHY the model predicted X and not Y. [e.g., explain why the model thinks the person has a particular disease; or explain the reason for a loan denial]
Additionally, when iterating and trying to improve your model, it is an excellent practice to go over some predictions and understand WHY the model is performing poorly in some instances.
Interpretability techniques can help in both cases — they inform “the why behind your model’s predictions.”
A fundamental interpretability technique is the “Feature Importance” in decision trees based models. It shows what features matter the most to your model. However, it does not provide enough clarity to explain specific predictions.
For that, you can use techniques that provide “local interpretability.” The most well-known are LIME and SHAP. The remarkable thing is that they are model-agnostic — in other words, they work for any ML model. I recommend diving deeper and understanding how they generate local interpretability instead of using them blindly.

There are, of course, many others. Some of them are specific — Such as Layer-wise Relevance Propagation (LRP) for Neural Networks—but I advise focusing on LIME and SHAP, as they already cover the most common use cases.
2. AI Fairness
All models learn some bias. In a certain way, bias is necessary for making predictions (you learn them through your data and exploit them to forecast the future).
However, not all bias is wanted. For instance, a model that favors a particular ethnicity over others is unacceptable — e.g., only approving loans for white people. In other cases, using ethnicity can help provide a more accurate prediction for them — such as in a medical application.
Learning to identify and mitigate unwanted bias is vital for those applications, and AI Fairness is the field that takes care of this. I have published an article that goes through a more detailed explanation of how to identify and mitigate those biases — you can read it here.
Anyway, here is a fantastic table referencing some of the AI Fairness techniques:
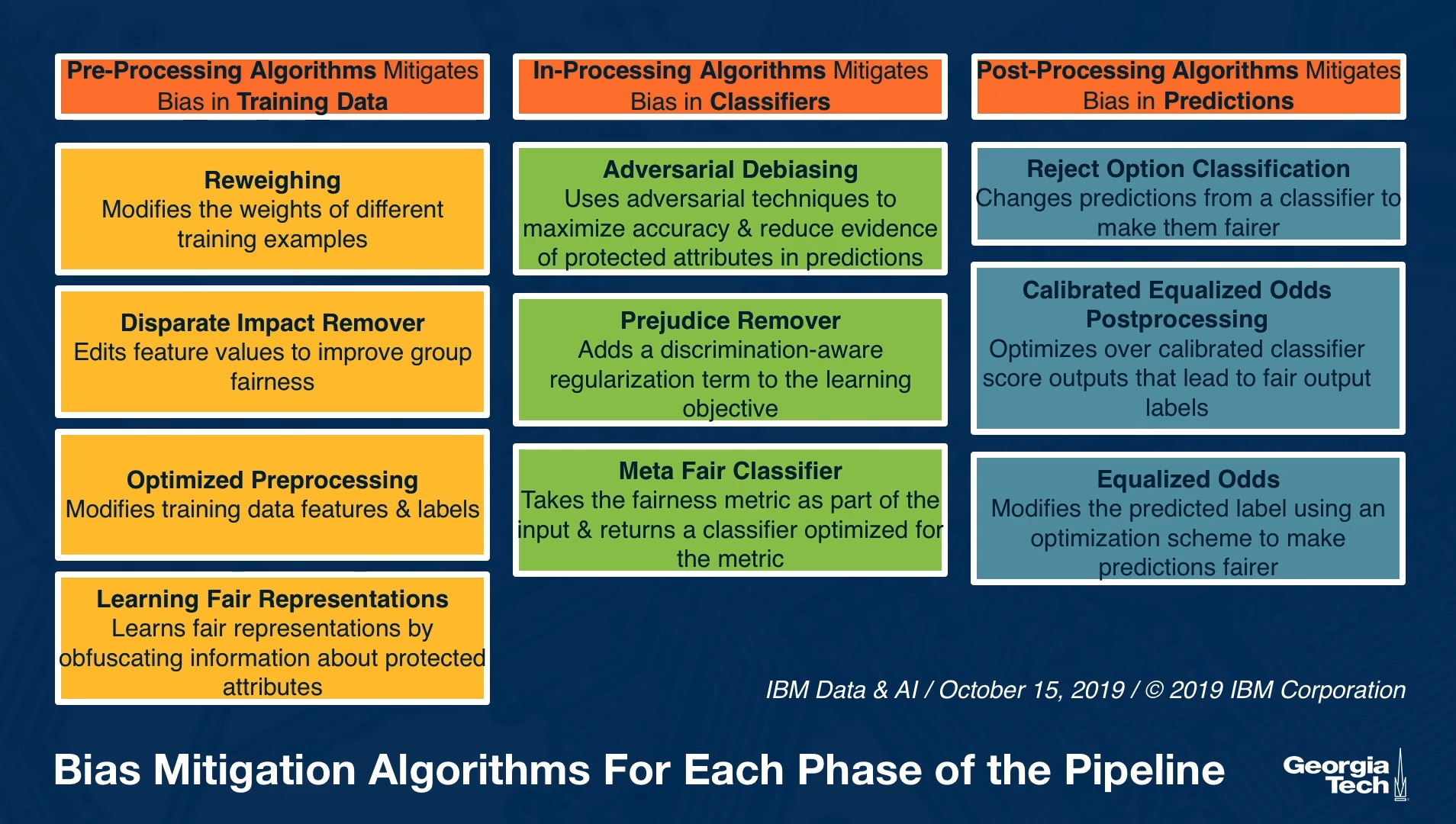
3. AI Privacy

Models learn from data to make their predictions. Sometimes, that data can be sensitive. Some malicious people can try to use your model to reverse engineer some information about the dataset you used to train it on, for instance:
Membership Inference: Identify whether a person was in the dataset.
Model Inversal: Construct the original dataset (entirely or partially).
Statistical Inferences: Estimate feature averages, distributions, etc.
These three are only some examples of what attackers might want to do with your model. Again, this is especially true for sensitive data (people info, credit card info, medical records, etc.)
You can use AI Privacy techniques to make your model more robust to these attacks. I recommend studying the following topics to start:
Data Cleaning: If you can, remove or encrypt sensitive data.
API Hardening: Making it hard for attackers to make a bunch of inferences with your model.
Differential Privacy: Change your data and model to guarantee certain privacy levels, typically in exchange for performance. Try to understand how much privacy you need for your application.
Federated Learning: A way to train models in a distributed framework without directly sharing data, helping with other data privacy concerns.
4. AutoML

AutoML is the field that tries to automate parts of the Machine Learning pipeline to improve the model training process, making it faster and potentially better.
Feature Engineering: Creating features is typically an extensive process. Auto Feature Engineering tools try to create and evaluate them for you. (Tooltip: featuretools)
Pre-processing + model Selection + Hyperparameter Optimization: Instead of manually setting parameters, these techniques provide optimized searching solutions to find the best combination for your problem. (tooltip: auto-sklearn)
5. Causal Inference

Sometimes, instead of focusing on predictions, we might want to choose the right “treatment” in an application. For instance:
Choosing Model A vs. Model B
Decide how much discount to give to a customer
Define a customer credit limit
If you are entirely new at this, I recommend starting with the basics of A/B testing, which should help you design practical experiments.
Afterward, my golden recommendation is the Causal Inference for the Brave and True, which goes in-depth into causality with convenient python examples. You will there learn about estimating the “Conditional Average Treatment Effect“ (CATE) using models (namely, X-learners, S-learners, and T-learners)
6. Fast Training
Especially for those working with larger models that take a long time to train, looking for ways to speed up the training is vital to achieving results more quickly.
For that, we can train a model way quicker through different techniques, such as:
Learning Rate Finders: For instance, using a Cyclical Learning Rate (CLR) to arrive at convergence with fewer iterations (image below)
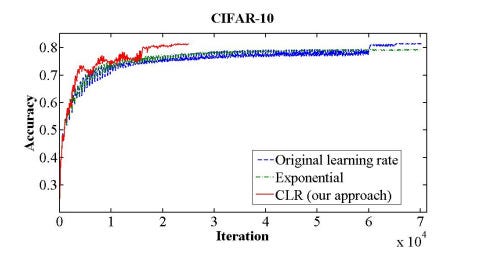
Mixed-Precision: Instead of using full-precision of the GPU operations, reduce it fully or partially (mixed) to half-precision (fp16), making the calculations faster and resulting in less GPU memory usage. Of course, a reduced precision may impact your final model performance.
Model Compression: Reducing the model, for instance, by cutting down weights (model pruning), can also help with speed. Also, some research shows that larger, sparse models are often better than smaller, dense ones.
7. Unstructured Data

Most people start in the field by tackling structured data (tables). However, dealing with unstructured data can provide some exciting modeling opportunities for you.
In all of them, you can work with a more classical approach (such as using libraries to extract features from them) or use Deep Learning. For Deep Learning, I recommend sticking to PyTorch or Tensorflow (in doubt? Pick PyTorch).
Some additional libs I recommend by data type:
Images: Scikit-image, OpenCV, and TorchVision
Audio: Librosa, TorchAudio and SpeechBrain
Text: SpaCy, Sklearn, and HuggingFace Transformers.
Finally
While there are many other exciting topics in Machine Learning, these 8 are my top recommendations based on how useful they can be for your projects and careers.
Hopefully, you find some of them interesting or useful! :)