
Fairness Crusade: Fighting AI Bias
A story on how I faced the problem of biased AI models, with tips for your future endeavors.

Identifying the Problem
There I was, early in my career, working on a freelance machine learning project for a bank. I was posed with the challenge of creating their loan approval system: for a beginner, this project should sound pretty simple, right? It is a classification model that tries to identify which customers are “good” (e.g., lucrative) and which aren’t.

Given that the company had a simple policy for customer application approval based on credit bureau scores and data on which customers paid their loans or defaulted, I had enough data to train an initial model. But then… I started reflecting.
You know, loans can change lives. Sometimes loans are made to pay off an unexpected health expense, other times when someone’s primary income gets compromised, or even to start a business. Therefore, when you deny a loan, you are potentially closing up a life-changing opportunity for them. At the same time, it’s business. You cannot simply approve all loans; otherwise, the bank would rapidly go bankrupt due to default.
Can I use any features? Well, not really. If we have, say, a gender or race feature, the model will directly learn to be more discriminative towards either group, which would ultimately make it benefit certain groups over others.
I tried excluding those features, but when I analyzed the “feature importance” given by my model, I found that the most relevant feature was one related to the person's region. And upon further investigation, I discovered that pretty much all areas with higher black people's presence ended up being denied more.
Why does it matter? You see, the model still favors one group over the other. It might even have data to back that up (let’s say black people have a significantly higher default rate), but this poses mainly three problems:
i) Group Discrimination: If the other characteristics are the same for a white and a black person, the model could deny the black person just because they live in a black-dominated neighborhood, which is unfair [and it is also a crime in most countries - as it configures racism];
ii) Feedback Loop Problem: By denying more black people, we end up creating a vicious cycle: we have fewer data about them (because we only know “good” customers after they paid a loan in total), so when retraining, we won’t learn more about them (you can read more about degenerate feedback loops here).
iii) Opportunity Loop: Similarly, by approving fewer loans to a group, fewer people in that group will be able to change their lives with the loans they sought. This also intensifies the disparity of opportunities, worsening the situation in the long run.
So, I established: I would try not to use features that directly or indirectly identify a protected group (gender, race, age, etc.). But… There are correlations everywhere.
For instance, we could have salary disparity among the groups, and a lower salary could be connected to females, whereas higher wages could be tied to males. If our model learns to reject most low-salary people, we are falling again into the same trap.
Measuring Bias
Even though I identified the “bias problem” above by inspecting my model and thinking about the business domain, the fact that I couldn’t tell “how unfair” my model was started to bother me.
I started with a straightforward way of measuring it: Opportunity Inequality. I used my model to predict the test data and then checked the loan approval rate for each protected group. The difference between the “highest approval rate” and the “lowest approval rate” became this “Opportunity Inequality” measure.
Later in my career, I discovered a better name for this one — statistical parity difference — and other metrics as well, such as:
Predictive Parity: Difference % of correct predictions for each group
Statistical Parity: Difference in the rate of favorable outcomes
Disparate Impact: Privileged Outcome Ratio / Unprivileged Outcome Ratio
Theil Index: Entropy of Benefit for all individuals

Achieving Fairness
After seeing that my initial model statistical parity was terrible, I started thinking about ways to reduce it.
I started tweaking my features: I conducted a feature selection to get to a model with a good enough statistical parity. However, this process created a pretty inaccurate model, as I was left with few features that would not serve the business purpose.
Then, changing the model: I tried to change the model and play with hyperparameters to achieve something with less variance so it would have less of a problem fixating on the more problematic attributes. Not enough.
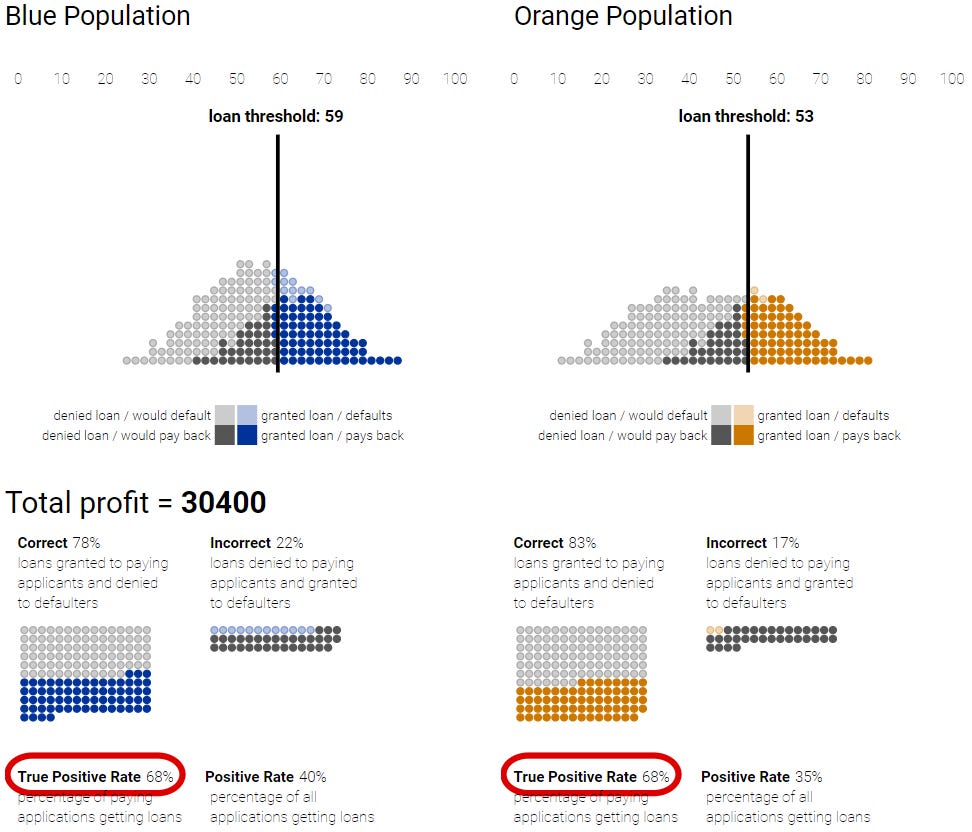
Finally, the output: You can see the fairness metrics impacts by tweaking the threshold for each protected group. I tried the two following approaches:
Demographic Parity: Trying to get the same amount of loans approved in each group. However, this led to a very unprofitable model, as the groups in my case had a very different “rate of paying the loans back.”
Opportunity Parity: To find an “Equal Opportunity Rate” for each group, I found custom thresholds that maintain the same percentage of approved loans to each group, considering only those that can pay the loan (True Positive Rate). This was the best approach, achieving accuracy, profit, and equality, and it also had the benefit of being very easy to implement and maintain.
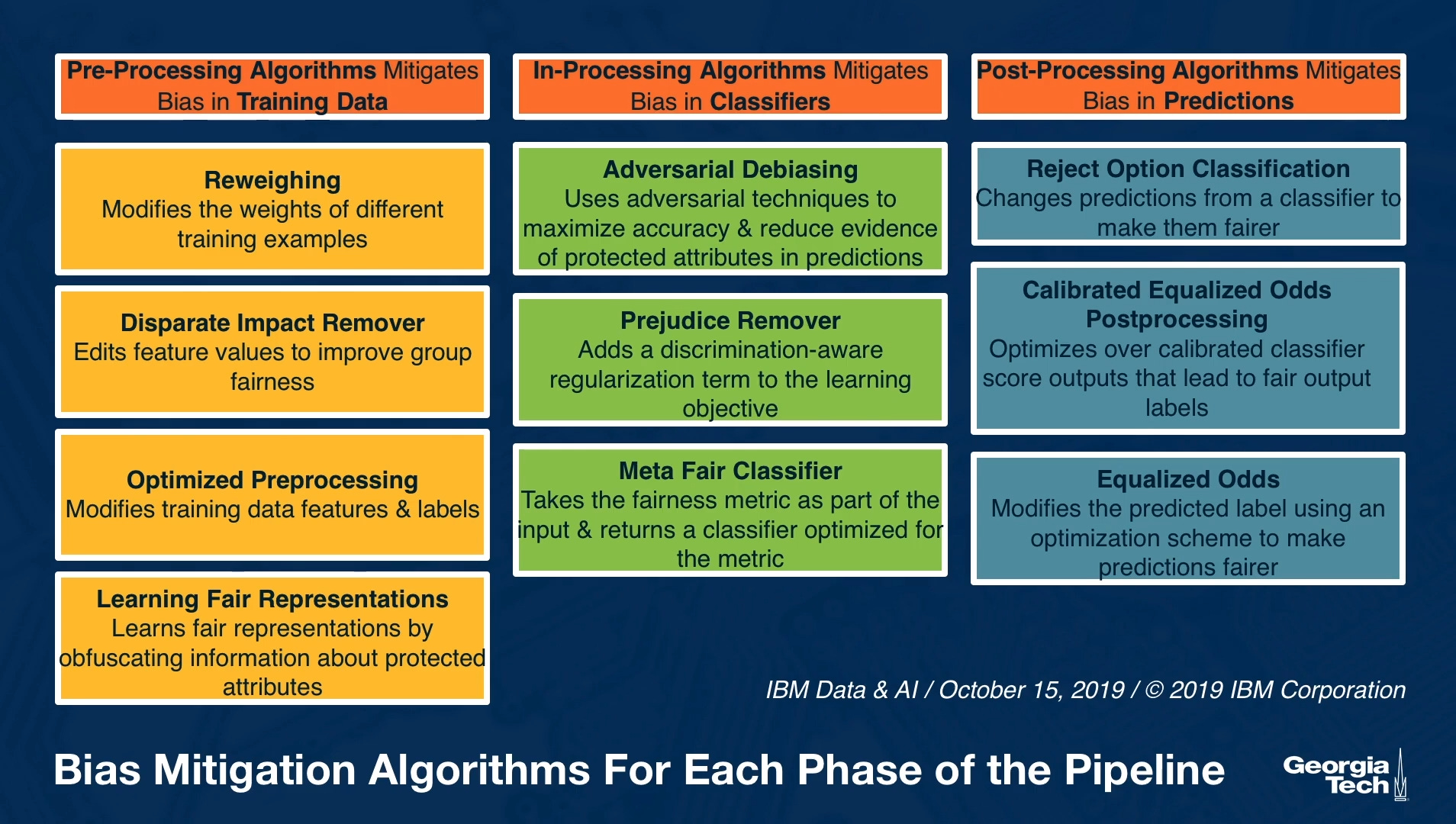
Going Beyond
There are other exciting approaches to promoting AI Fairness I learned after this project. I am not going into them super in-depth, but I will provide tools to implement them (searching their name on google should do the trick to dive a bit deeper)
Practical Tips:
Simple first: Even though terms like “Adversarial Debiasing” and “Meta Fair Classifier” are very appealing, I encourage Data Scientists to experiment first with post-processing techniques. It’s easier to understand and tune, you can use it on any trained model, and it’s easier to maintain - if the AI Fairness Metrics worsen with time, you can tweak the thresholds instead of going through a model retraining process.
Pre-processing techniques are neat. For instance, Disparate Impact Removal can change the distribution of a feature (say, salary) to become similar among your protected groups, making them indistinguishable. Therefore the model would not be able to favor one group over the other. However, you should also consider that if you tweak the data representations, your model’s interpretability will decrease, especially if you run this process on many features for different protected groups. Only go with them if this is not a concern for your application.

Identify the Root Cause: Sometimes, your bias comes from your “label.” For instance, if you have a classifier for “good candidate” vs. “bad candidate” based on approved candidates in interviews, you might carry the interviewers' bias. So, if historically, you favor one group over the others, the model will learn that trend too. In this case, even though the techniques presented here can help, it would be better to address the root cause — the bias the interviewers have.
Tools
Alright. No one wants to implement those Fairness algorithms from scratch. I will list my favorite fairness tools here:
aif360: Developed by IBM, it has the most used AI Fairness metrics and mitigation algorithms, both available in Python and R.
Responsible AI Toolbox: developed by Microsoft, it has tools to identify, diagnose and mitigate fairness issues.
Fairlearn: Another project I used (scikit-fairness) merged with them. Their documentation has excellent explanations, and it also has metrics and mitigation techniques.
Tensorflow Fairness Indicators: If you are developing deep learning models with TensorFlow, this tool can easily integrate to provide your fairness metrics.
Interpretability tools: such as SHAP-values and LIME, can show which features are most relevant in your models, which can help in identifying potential fairness problems. I’ll dive deeper into interpretability in a future article.
Conclusion
I had the opportunity to face this challenge early on and then faced it again in different scenarios. Apart from the specific AI Fairness techniques, the most important thing is to remember that all we want is to ensure that the model does not carry undesirable bias.
Many businesses don’t care about this, but if you are a data scientist, I highly recommend you introduce this topic to your peers and measure the fairness of current models of your company to highlight whether there is a possible problem. Even if the businesses don’t mind, many will at least fear a backlash from regulators in their industry or the general public calling the company “discriminatory.”
Nevertheless, the approaches should depend highly on what you apply them to. For instance, if a Face Identification system struggles to identify one race over the other, you should look at the “Prediction Parity.” Instead of using the techniques I presented here, you could come up with something that works for this problem — such as adding more examples of the group with less accuracy to your training data.
In other cases, “fairness” might not make that much sense. Suppose you developed a disease-detecting model that uses the person's gender and age as features. In this case, there is no problem in using those features, as we are not favoring one group over the other; we are simply adding contextual information that improves the model for everyone (the biology of each impacts the disease-likelihood).
Many AI systems can drastically impact people’s lives. Please do your best to create them responsibly.
If you enjoyed it, subscribe. In future articles, I will cover other aspects of “Responsible AI” (such as privacy and security).